参考博客链接:
机器学习:监督学习、无监督学习、半监督学习、强化学习-CSDN博客
一文读懂强化学习:RL全面解析与Pytorch实战_强化学习实战-CSDN博客
有监督学习
监督学习的定义
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。
在监督学习中训练数据既有特征又有标签,通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
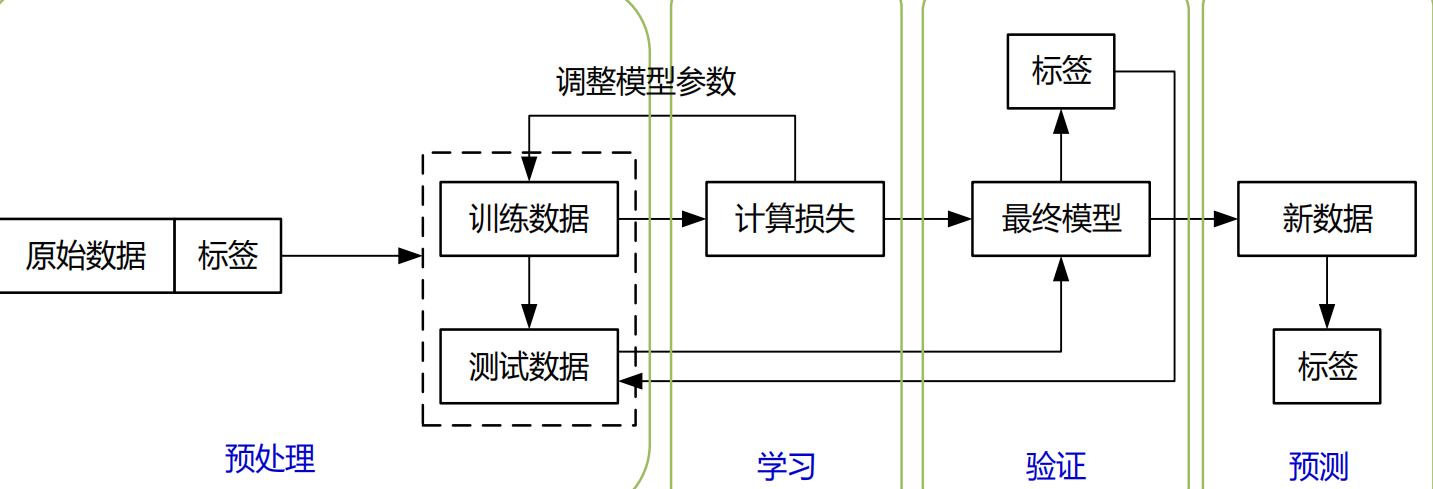
简单理解:可以把监督学习理解为我们教机器如何做事情。给机器许多“带答案”的样本,让它学习规律,以便遇到新数据时可以预测答案。
监督学习的公式理解
输入:\(X\)
输出(答案标签):\( y \)
学习的模型(函数):\( f(\cdot) \)
目标:让模型学到一个函数:
\[f(x) \approx y\]使得模型输入 x 后能输出接近正确答案 y
学习过程(找最佳参数 θ):
\[\min_\theta L(f_\theta (x), y)\]\( L \) 是损失函数(计算预测误差),目的是让误差越小越好
监督学习的类别
监督学习任务主要包括分类和回归两种类型,在监督学习中,数据集中的样本被称为“训练样本”,并且每个样本都有一个输入特征和相应的标签或目标值。
分类: 在分类任务中,目标是将输入数据分到预定义的类别中。每个类别都有一个唯一的标签。算法在训练阶段通过学习数据的特征和标签之间的关系来构建一个模型。然后,在测试阶段,模型用于预测未见过的数据的类别标签。例如,将电子邮件标记为“垃圾邮件”或“非垃圾邮件”,将图像识为“猫”或“狗”。
回归: 在回归任务中,目标是预测连续数值的输出。与分类不同,输出标签在回归任务中是连续的。算法在训练阶段通过学习输入特征和相应的连续输出之间的关系来构建模型。在测试阶段,模型用于预测未见过的数据的输出值。例如,预测房屋的售价、预测销售量等。
监督学习的常见算法
① 线性回归 Linear Regression
② 逻辑回归 Logistic Regression
③ k 近邻算法 KNN
④ 决策树 Decision Tree
⑤ 随机森林 Random Forest
⑥ 支持向量机 SVM
⑦ 朴素贝叶斯 Naive Bayes
⑧ 梯度提升树 GBDT
⑨ XGBoost / LightGBM / CatBoost
⑩ 深度学习:如 CNN、RNN、Transformer
这些都可用于监督学习,只要有标签数据。
无监督学习
无监督学习的定义
定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。
在无监督学习中数据只有特征无标签,是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
简单理解:比起监督学习,无监督学习更像是自学,让机器学会自己做事情。
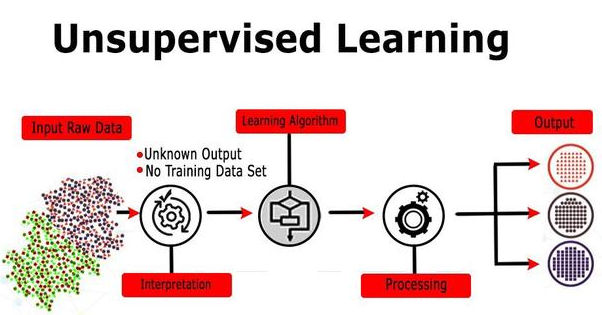
无监督学习的公式理解
\[\min_\theta ; L(X, f_\theta(X))\]\(X\):输入数据
\(f_\theta\):模型
\( L \):让模型学到某种规律的损失函数
无监督学习就是设计一个损失,使模型在没有答案的情况下学到结构。
无监督学习的类别
无监督学习的特点是在训练数据中没有标签或目标值。无监督学习的目标是从数据中发现隐藏的结构和模式,而不是预测特定的标签或目标。无监督学习的主要类别包括以下几种:
聚类:聚类是将数据样本分成相似的组别或簇的过程。它通过计算样本之间的相似性度量来将相似的样本聚集在一起。聚类是无监督学习中最常见的任务之一,常用于数据分析、市场细分、图像分割等。
降维:降维是将高维数据转换为低维表示的过程,同时尽可能地保留数据的特征。降维技术可以减少数据的复杂性、去除冗余信息,并可用于可视化数据、特征提取等。常见的降维方法有主成分分析(PCA)和t-SNE等。
关联规则挖掘:关联规则挖掘用于发现数据集中项之间的关联和频繁项集。这些规则描述了数据集中不同项之间的关联性,通常在市场篮子分析、购物推荐等方面应用广泛。
异常检测:异常检测用于识别与大多数样本不同的罕见或异常数据点。它在检测异常事件、欺诈检测、故障检测等领域有着重要的应用。
无监督学习在数据挖掘、模式识别、特征学习等领域中发挥着重要作用。通过发现数据中的结构和模式,无监督学习有助于我们更好地理解数据,从中提取有用的信息,并为其他任务提供有益的预处理步骤。
无监督学习的常见算法
① 聚类,代表算法:K-means、DBSCAN、GMM,作用:自动分组
② 降维,代表算法:PCA、t-SNE、UMAP,作用:压缩维度、特征提取
③ 异常检测,代表算法:One-Class SVM、LOF、Isolation Forest,作用:识别异常数据
④ 关联分析,代表算法:Apriori、FP-growth,作用:挖掘关联规律
半监督学习
半监督学习的定义
半监督学习就是:有一小部分样本有答案,另一大部分没答案,让机器一起利用它们来学习。目标是利用同时包含有标签和无标签的数据来构建一个模型,使得模型能够在测试阶段更好地泛化到新的、未见过的数据。
半监督学习介于监督学习和无监督学习之间。在半监督学习中,训练数据同时包含有标签的数据和无标签的数据。通常情况下,获取带有标签的数据可能会比较昂贵或耗费大量的时间,而采集无标签的数据则相对容易和便宜。
无标签的数据可以起到两个重要作用:
利用未标记数据的信息:未标记数据可能包含对数据分布、结构和隐含特征的有用信息,这些信息可以帮助模型更好地进行泛化。
利用标记数据的传播效应:通过利用标记数据与无标签数据之间的数据分布相似性,可以通过传播标签信息到无标签样本,进而增强模型的性能。
半监督学习通过充分利用未标记数据,可以在某些情况下显著提高模型的性能,并且有助于在数据有限的情况下构建更加健壮和泛化能力强的机器学习模型。
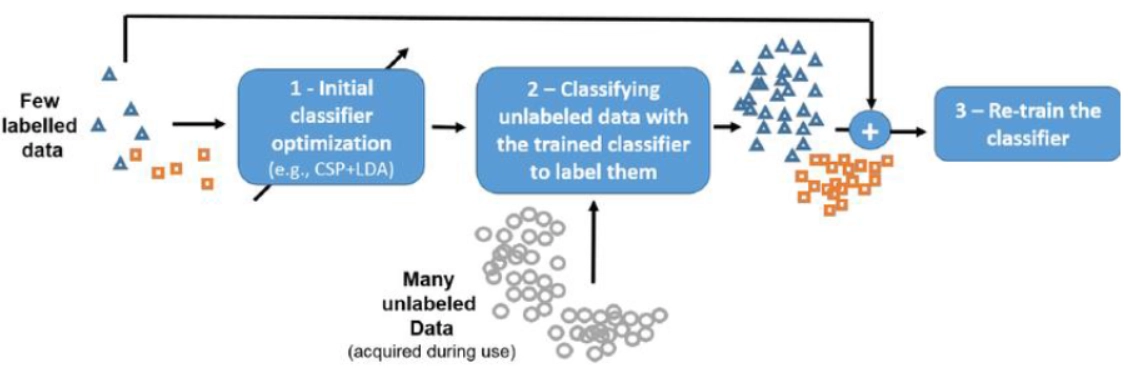
半监督学习的公式理解
假设模型是:
输入:\( x \) 有标签的样本:\( (x_i, y_i) \) 无标签样本:\( x_j \)
\[\min_\theta \mathcal L =\mathcal L_{\text{sup}}(x_i, y_i) + \lambda \mathcal L_{\text{unsup}}(x_j)\]\( \mathcal L_{\text{sup}} \):有监督损失(使用有标签的数据) \( \mathcal L_{\text{unsup}} \):无监督损失(使用没标签的数据) \( \lambda \):权重平衡两个损失贡献
监督损失通常使用交叉熵:
\[\mathcal L_{\text{sup}}= - \sum y \log f(x)\]意思是:预测越接近真实标签越好
无监督损失 \(L_{unsup}\)
常见做法:
* consistency consistency consistency(保持一致性) * pseudo labels(伪标签) * smoothness(光滑性约束)
\[\mathcal L_{\text{unsup}}= | f(x_j) - f(\tilde x_j) |^2\],意思是:模型对同一无标签样本的预测前后一致
半监督学习的类别
半监督学习是介于监督学习和无监督学习之间的一种学习方式,它利用同时包含有标签和无标签数据的训练集来构建模型。半监督学习的类别主要分为以下几种:
半监督分类:在半监督分类中,训练数据中同时包含带有标签的样本和无标签的样本。模型的目标是利用这些标签信息和无标签数据的分布信息来提高分类性能。半监督分类算法可以在分类任务中利用未标记数据来扩展有标签数据集,从而提高模型的准确性。
半监督回归:半监督回归任务与半监督分类类似,但应用于回归问题。模型通过有标签的数据和无标签数据进行训练,以提高对未标记数据的回归预测准确性。
半监督聚类:半监督聚类算法将有标签数据和无标签数据同时用于聚类任务。它们可以通过结合数据的相似性信息和标签信息,来更好地识别潜在的簇结构。
半监督异常检测:半监督异常检测任务旨在从同时包含正常样本和异常样本的数据中,利用有限的标签信息来检测异常。这在异常样本较少的情况下特别有用。
生成对抗网络(GANs)中的半监督学习:GANs可以被用于实现半监督学习。在这种情况下,生成器和判别器网络可以使用有标签和无标签的样本,以提高生成模型的性能。
半监督学习的常见算法
① 基于伪标签(Pseudo-label)的方法:用已训练模型给无标签数据产生“临时标签”,再用它们继续训练。
* Pseudo Labeling(最基本) * Self-Training(自训练) * FixMatch
② 一致性约束(Consistency Regularization)方法:对同一个样本,不管怎么增强、扰动,模型预测应该一致。
* Π-model * Mean Teacher * Temporal Ensembling * VAT(Virtual Adversarial Training)
③ 基于图的半监督学习(Graph-based SSL):样本之间关系由图表达,相似样本应该预测相似标签。
* Label Propagation * Label Spreading * Graph Neural Networks (GNN 也属于半监督框架)
④ 生成式半监督学习方法:利用生成模型帮助学习分布
* Semi-supervised GAN * Variational Autoencoder+SSL(SSVAE)
强化学习
强化学习的定义
定义: 强化学习是让一个智能体在环境中通过尝试和错误来学习行为策略。智能体通过与环境进行交互,根据奖励信号来调整其行为策略,以达到最大化累积奖励的目标。
在强化学习中,智能体不需要明确地告诉如何执行任务,而是通过尝试和错误的方式进行学习。当智能体在环境中采取某个动作时,环境会返回一个奖励信号,表示该动作的好坏程度。智能体的目标是通过与环境交互,学习到一种最优策略,使其在长期累积的奖励最大化。
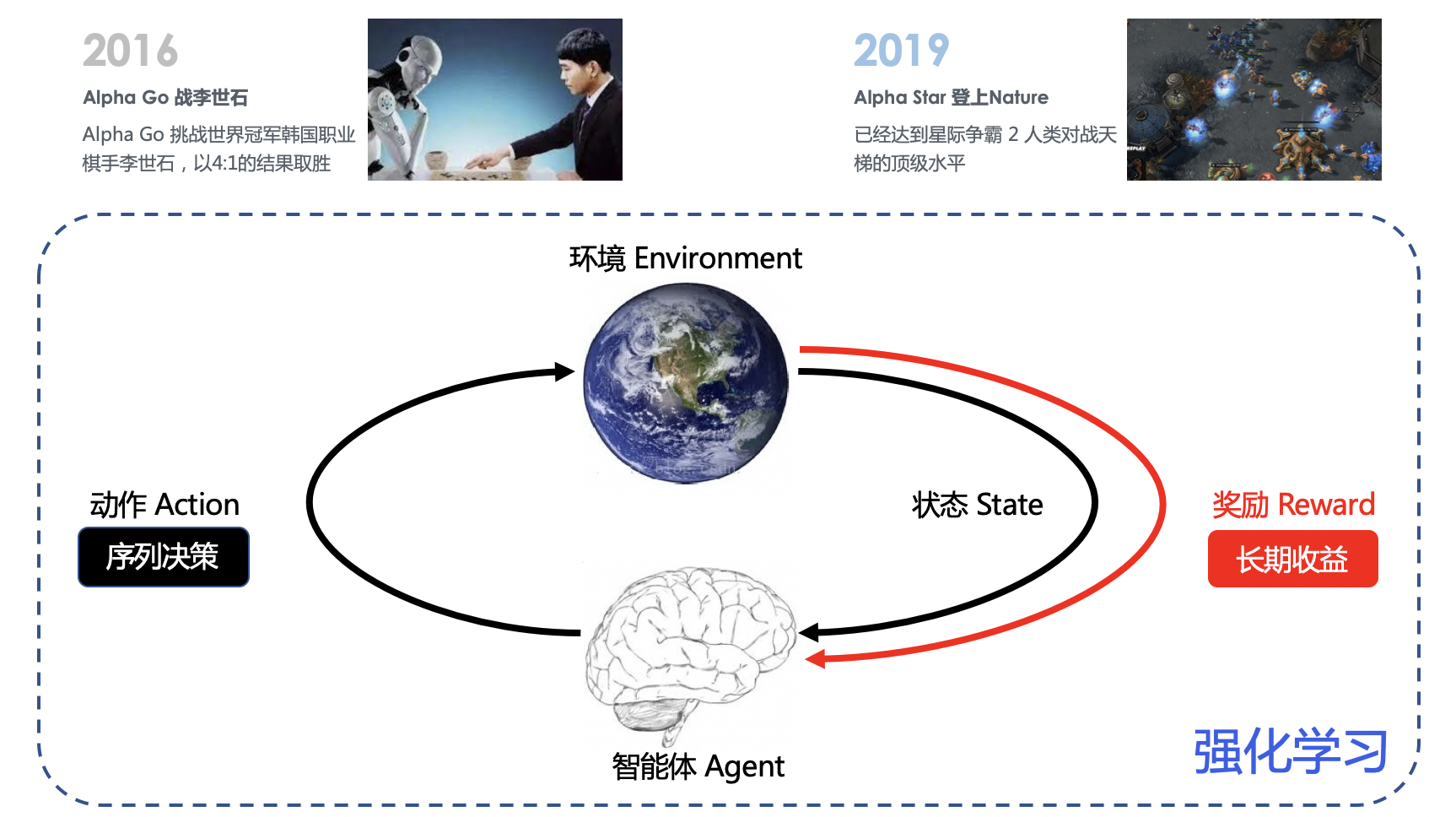
强化学习的框架主要由以下几个核心组成:
状态(State):反映环境或系统当前的情况。 动作(Action):智能体在特定状态下可以采取的操作。 奖励(Reward):一个数值反馈,用于量化智能体采取某一动作后环境的反应。 策略(Policy):一个映射函数,指导智能体在特定状态下应采取哪一动作。
这四个元素共同构成了马尔可夫决策过程,这是强化学习最核心的数学模型。 (1)智能体观察当前环境状态(state)。 (2)基于当前状态,智能体选择一个动作(action)。 (3)环境根据智能体的动作转换到新的状态,并返回一个奖励信号(reward)。 (4)智能体根据奖励信号更新其策略,以便在将来的决策中获得更好的奖励。 (5)重复以上步骤,直到智能体学习到一个使其获得最大累积奖励的策略。
强化学习的类别
强化学习是一种机器学习方法,根据智能体(agent)与环境的交互来学习适当的行为策略以最大化累积奖励。强化学习的类别主要可以分为以下几种:
基于值的强化学习:基于值的强化学习方法旨在学习价值函数,即给定状态或状态-动作对的值,代表了智能体在该状态或状态-动作对上能够获得的累积奖励的估计值。这些方法通常通过使用贝尔曼方程或其变种来更新价值函数,并使用它来选择动作。
基于策略的强化学习:基于策略的强化学习方法直接学习策略函数,即将状态映射到动作的映射。策略可以是确定性的(对于每个状态只输出一个动作)或是概率性的(对于每个状态输出动作的概率分布)。这些方法通常通过梯度上升方法来更新策略参数,以最大化累积奖励。
基于模型的强化学习:基于模型的强化学习方法学习环境的模型,即从状态和动作预测下一个状态和奖励。然后,它可以使用学到的模型进行规划和决策,而无需真实地与环境进行交互。这样可以提高样本效率和规划效率。
深度强化学习:深度强化学习将深度神经网络与强化学习相结合。它通常使用深度神经网络来近似值函数或策略函数。深度强化学习在处理高维状态空间和动作空间的任务时表现出色。
多智能体强化学习:多智能体强化学习研究多个智能体在相互作用环境中的学习问题。在这种情况下,每个智能体的策略和动作会影响其他智能体的状态和奖励,因此学习变得更加复杂。
强化学习的常见算法
Q-Learning:Q-Learning是一种基于值的强化学习算法。它通过学习一个值函数(Q函数)来表示在给定状态下采取某个动作的累积奖励。Q-Learning使用贝尔曼方程更新Q值,并使用贪心策略来选择动作。
SARSA:SARSA是另一种基于值的强化学习算法。它与Q-Learning类似,但不同之处在于它在学习和决策阶段都使用当前策略的动作来更新Q值。
DQN(Deep Q Network):DQN是一种深度强化学习算法,结合了深度神经网络和Q-Learning。它使用深度神经网络来近似Q函数,通过经验回放和目标网络来稳定训练。
A3C(Asynchronous Advantage Actor-Critic):A3C是一种基于策略的强化学习算法,它结合了Actor-Critic方法和异步训练。A3C使用多个智能体并行地训练,以提高样本效率。
PPO(Proximal Policy Optimization):PPO是一种基于策略的强化学习算法,它通过限制更新幅度来稳定训练。PPO在深度强化学习中表现出色,并被广泛应用于各种任务。
TRPO(Trust Region Policy Optimization):TRPO是另一种基于策略的强化学习算法,它使用限制步长的方法来保证更新策略时不会使性能变差。