AlexNet 学习
概论
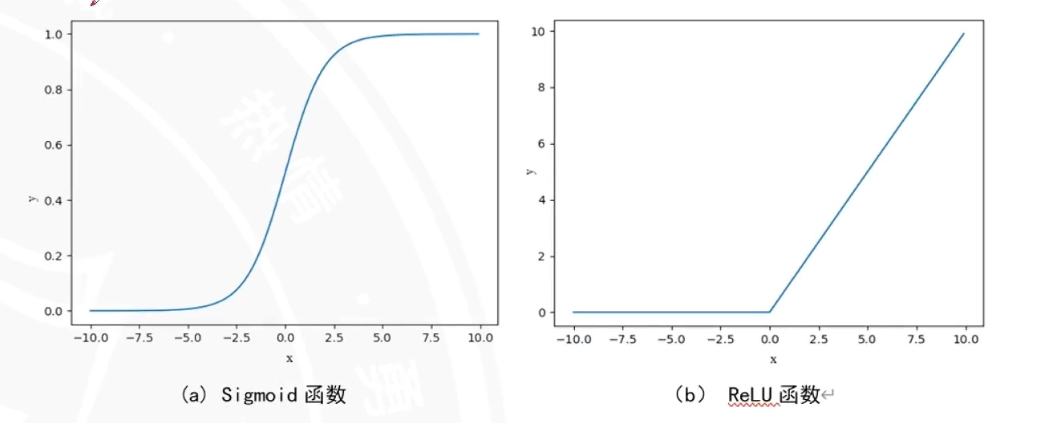
2012年提出,在ImageNet图像分类比赛中取得优异成绩,它通过使用RLU激活函数,数据增强和dropout正则化技术,极大地提升了图像识别的精度和速度。AlexNet的成功标志着深度学习在计算机视觉领域的突破,推动了后续更多先进网络结构的研发。实际上也是DL的导火索。
论文出处:ImageNet classification with deep convolutional neural networks | Communications of the ACM
原理学习
卷积的计算与属性
数据增强
为了解决过拟合的问题,进行数据增强,旋转、裁剪、对比度等等

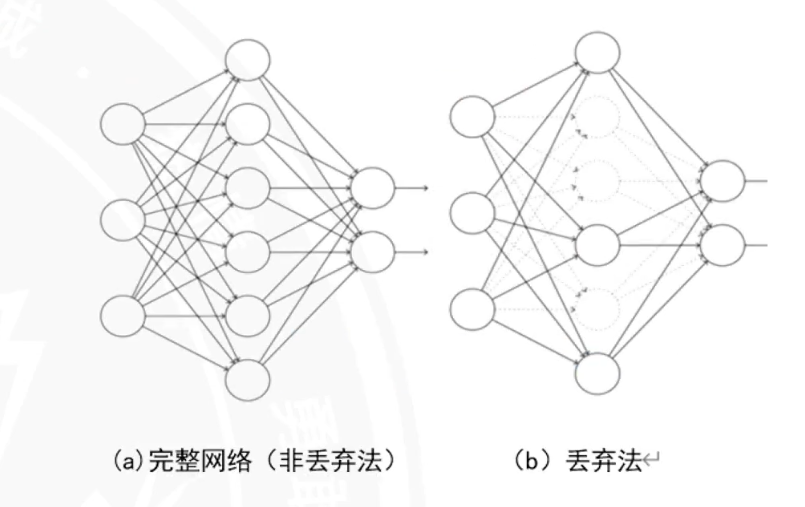
Dropout
Other question
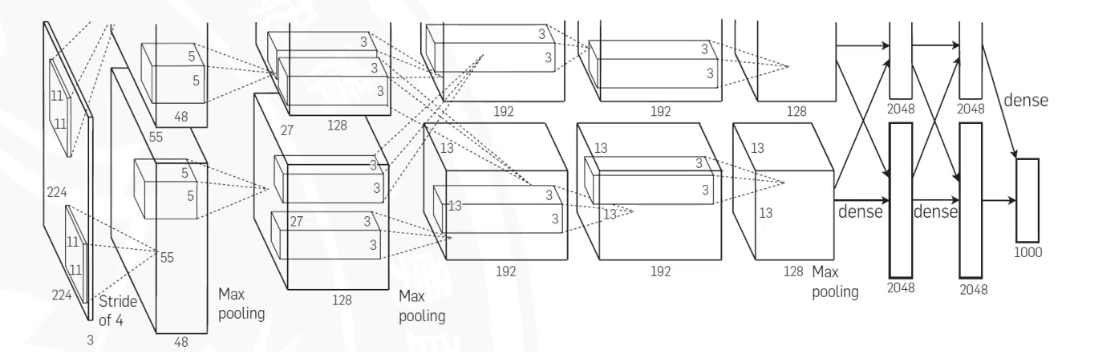
- 多GPU实现,是因为当时硬件条件太差,无奈之举,现在已经不需要这样了,但是有GCNN后续问世,也是一种新训练方式。图中虚线feature map的交互(复制)是为了让模型更统一。
- 局部相应归一化,后续被BN/LN取代,只是一个过渡产物。
代码实现
主要是学习“alexnet.py”文件,其他的训练脚本等等具有通用的性质。
导入库
| |
torch.nn是PyTorch中用于构建神经网络的核心模块,nn是其缩写。它提供了大量预定义的神经网络层(如卷积层nn.Conv2d、全连接层nn.Linear、激活函数nn.ReLU、池化层nn.MaxPool2d等)、损失函数(如nn.CrossEntropyLoss、nn.MSELoss)以及模型容器(如nn.Sequential)。 - 通过nn模块,开发者可以快速搭建各种神经网络结构,无需手动实现底层运算。
torch是PyTorch的主模块,包含了框架的核心功能。提供了张量(Tensor)数据结构(类似多维数组,是PyTorch的基本运算单位)、自动求导(torch.autograd)、GPU加速支持、数据加载工具(torch.utils.data)等。所有PyTorch的核心操作(如张量运算、模型训练流程控制)都依赖于这个模块。
torchsummary是一个第三方工具库,用于可视化神经网络的结构和参数信息。调用summary(model, input_size)可以输出模型各层的名称、输入输出形状、参数数量等,帮助开发者快速了解模型结构是否符合预期,尤其适合调试复杂网络。例如,对于CNN模型,它可以清晰展示每一层卷积、池化后的特征图尺寸变化,便于检查网络设计是否合理。
类定义与初始化
| |
num_classes=1000:默认分类类别数为1000
init_weights=False:是否初始化权重的开关
特征提取部分
这部分由卷积层、激活函数和池化层组成,用于从图像中提取特征:
| |
nn.Sequential:按顺序包装多个网络层
卷积层参数说明:nn.Conv2d(输入通道数, 输出通道数, 卷积核大小, 步长, 填充)
nn.ReLU(inplace=True):激活函数,inplace=True表示原地操作节省内存
nn.MaxPool2d:最大池化层,用于降低特征图尺寸
AlexNet中仅在第1、2、5个卷积层后使用池化,而第3、4个卷积层后不使用,主要出于以下考虑:
(1)避免特征过度压缩,前两个卷积层的卷积核较大(11×11、5×5),步长也较大(4、默认1),输出的特征图尺寸仍有压缩空间(如第一层从224×224→55×55,池化后→27×27)。而第3、4个卷积层使用3×3的小卷积核,且步长为1、padding=1,输出特征图尺寸与输入相同(13×13)。此时若加入池化,会将特征图压缩到6×6左右,但这两层的作用是细化特征提取,过早压缩会丢失细节信息。
(2)平衡特征提取深度与计算量,卷积层的核心作用是增加特征维度(通道数),池化层的作用是降低空间维度。两者需要交替配合,避免参数爆炸。第3、4层的通道数从256→384→384,处于特征维度提升阶段,此时保持空间尺寸(13×13)可以让小卷积核捕捉更丰富的局部模式。若在此处池化,会导致后续特征计算的基础空间分辨率不足。
(3)遵循先压缩大尺寸,后保留细节的逻辑,输入图像(224×224)尺寸较大,前两层通过大卷积核+池化快速压缩空间尺寸(从224→55→27→13),减少冗余计算。当尺寸压缩到13×13后,第3、4层专注于用小卷积核“深耕”特征,此时不需要再压缩尺寸。最后在第5个卷积层后再次池化,将尺寸从13×13→6×6,为后续全连接层的“扁平输入”做准备(6×6×256 = 9216,是全连接层的合适输入维度)。
分类器部分
这部分由全连接层组成,用于将提取的特征映射到具体类别:
| |
nn.Dropout(p=0.5):在训练时随机丢弃50%的神经元,防止过拟合
nn.Linear:全连接层,参数为(输入特征数, 输出特征数)
前向传播方法
| |
定义了数据在网络中的流动路径
torch.flatten(x, start_dim=1):将卷积输出的多维特征展平为一维向量,以便输入全连接层
权重初始化方法
| |
为卷积层和全连接层设置不同的权重初始化策略
卷积层使用Kaiming正态分布初始化(适合ReLU激活函数)
全连接层使用均值为0、标准差为0.01的正态分布初始化
模型创建函数
| |
提供了一个便捷的函数来创建AlexNet模型实例
可以通过传入num_classes参数指定分类任务的类别数