CNN 学习
概论
CNN,即卷积神经网络(Convolutional Neural Networks),是一种深度学习算法,它在图像处理、视觉识别等任务中表现出色,但不仅限于图像领域。CNN模型的基础组件包括卷积层、池化层和全连接层。卷积层负责提取图像中的局部特征;池化层用于降低特征的空间尺寸,减少计算量并提供一定程度的位移和形变不变性(尽可能保留关键信息);全连接层则负责将网络中学习到的表示映射到最终的输出,如分类标签。
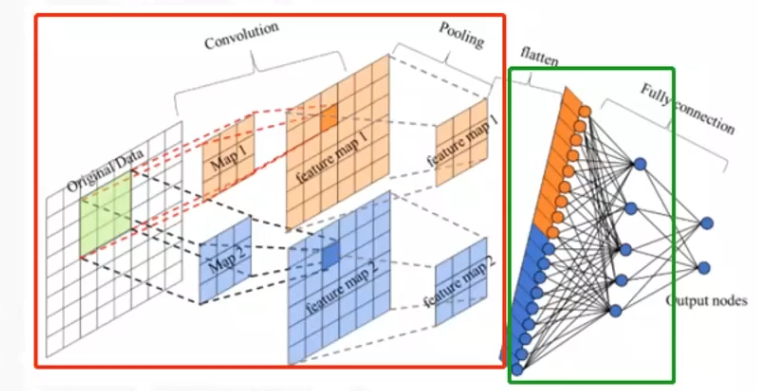
原理学习
卷积的计算与属性
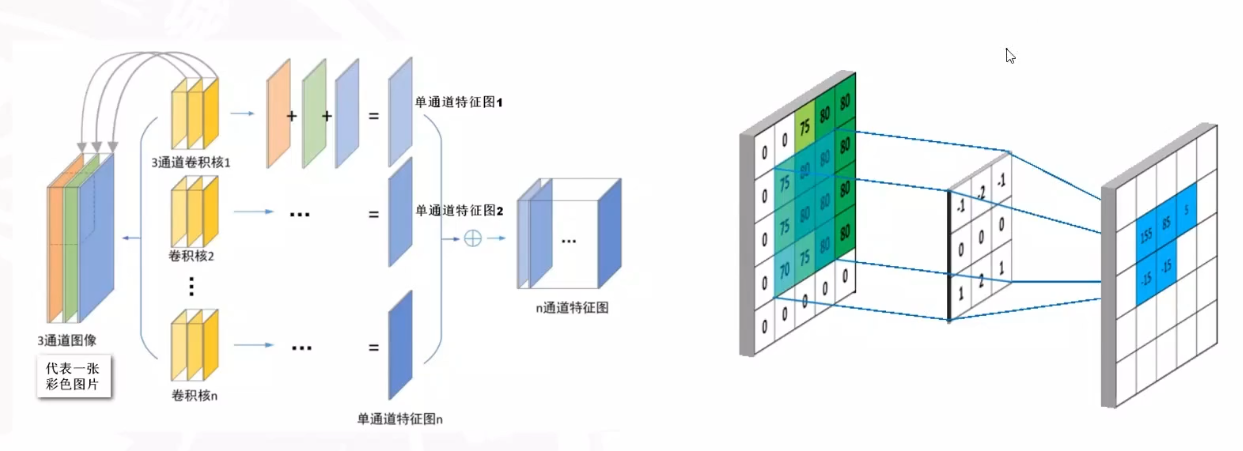
卷积核kernel可以上下左右滑动。
彩图是一个多维矩阵,RGB的3通道存储。
padding(填充)和stride(步长)
$$ N = \frac{W - F + 2P}{S} + 1 $$- \( N \):输出特征图的尺寸
- \( W \):输入特征图的尺寸
- \( F \):卷积核或池化核的大小
- \( P \):填充(padding)的大小
- \( S \):步长(stride)
使用卷积时,调用nn.Conv2d即可。
懒得计算结果的尺寸,调用nn.LazyConv2d即可,自动计算。
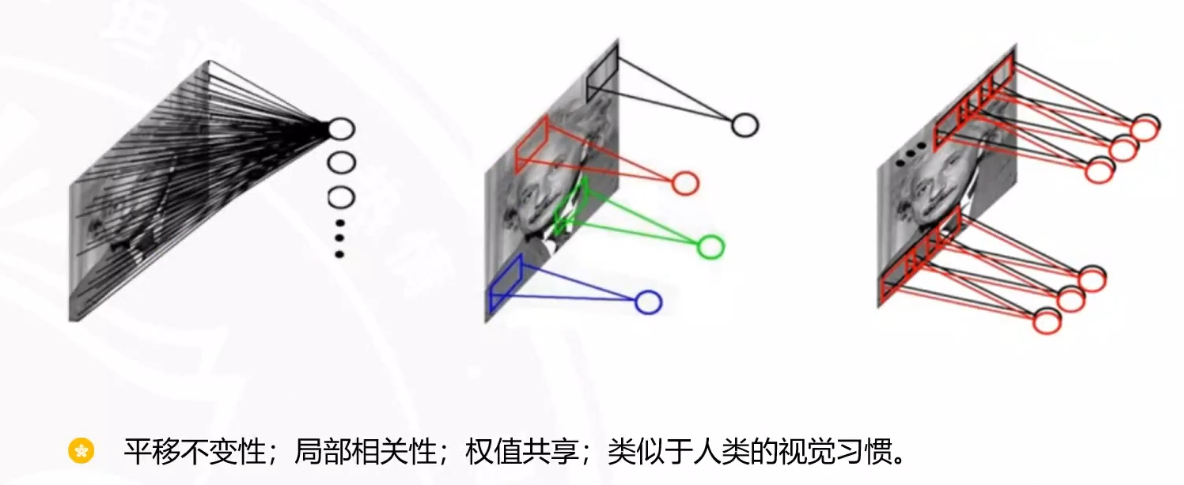
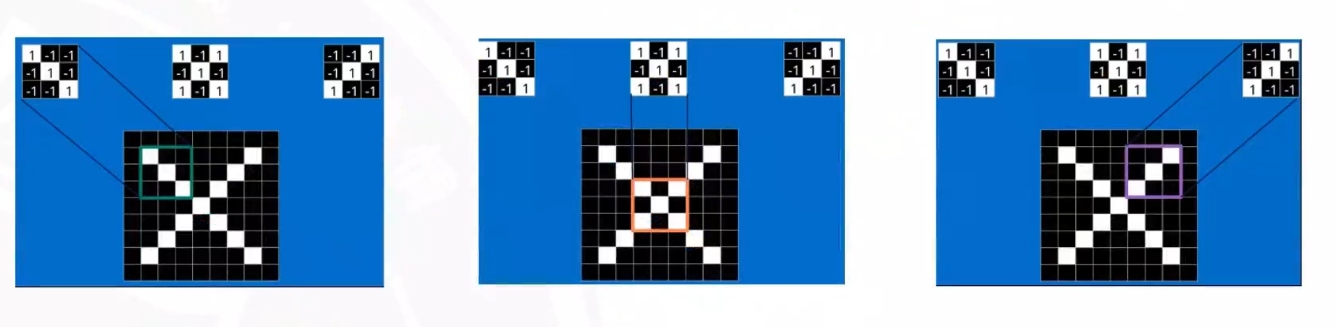
卷积的感受野
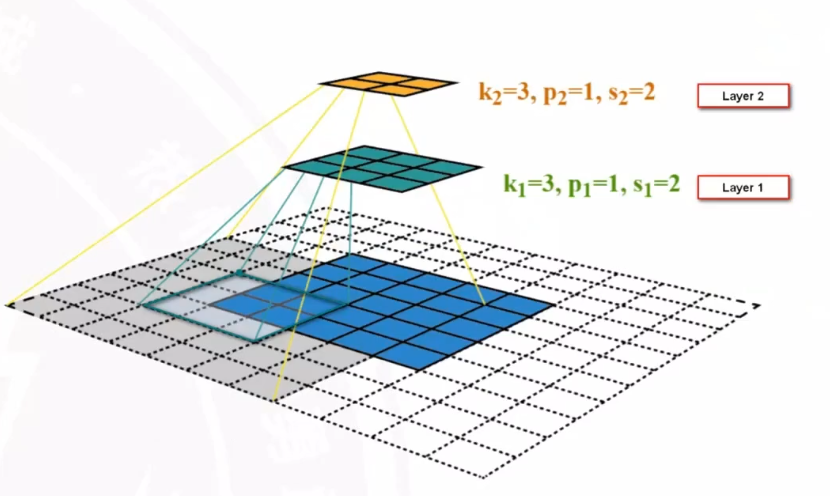
卷积特征提取的过程
Conv2d

图中上下两个网格分别代表输入特征图(蓝色)和卷积核(过滤器)(深绿色)。卷积的过程可以理解为:
- 让卷积核在输入特征图上滑动;
- 每次滑动时,计算卷积核与输入特征图对应区域的加权和;
- 这些加权和组成的新网格就是输出特征图。
官方定义的参数:
| |
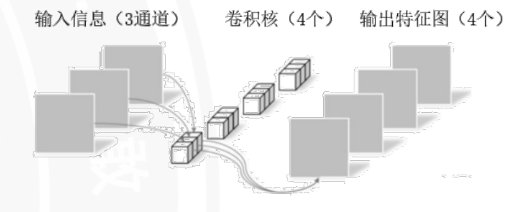
in_channels与out_channels
in_channels:输入数据的通道数。比如处理灰度图时是1,处理RGB彩色图时是3。out_channels:输出数据的通道数,等于卷积核的数量。每个卷积核会生成一个独立的输出通道,用于提取不同的特征(比如边缘、纹理、形状等)。
kernel_size:卷积核的大小
卷积核是一个小的矩阵(比如3x3、5x5),它决定了每次滑动时“看”输入特征图的范围。图中深绿色的小网格就是一个卷积核的可视化。
stride:步幅
卷积核在输入特征图上每次滑动的像素数。步幅越大,输出特征图的尺寸越小;步幅越小,输出尺寸越大(但计算量也会增加)。
padding:填充
在输入特征图的边缘添加“空像素”(通常是0),目的是保持输出特征图的尺寸(避免因卷积核滑动导致尺寸缩小过多)。比如padding=1就是在上下左右各加1层0。
dilation:空洞卷积(膨胀卷积)
控制卷积核内部的“间隔”。比如dilation=2的3x3卷积核,实际感受野相当于5x5(但参数数量还是3x3),常用于需要大感受野但又想减少参数的场景(比如图像分割中的Dilated Conv)。
groups:分组卷积
将输入通道和输出通道分成若干组,每组内独立做卷积。这是轻量化网络(如MobileNet)和大模型(如ConvNeXt)中常用的技巧,既能减少计算量,又能增强通道间的独立性。
卷积计算的核心公式为:
$$ \text{out}(N_i, C_{\text{out}_j}) = \text{bias}(C_{\text{out}_j}) + \sum_{k=0}^{C_{\text{in}}-1} \text{weight}(C_{\text{out}_j}, k) \star \text{input}(N_i, k) $$weight(C_out_j, k):第j个输出通道的卷积核,对应第k个输入通道的权重矩阵;input(N_i, k):第i个样本、第k个输入通道的特征图;$\star$:互相关操作(可以简单理解为“带权重的滑动求和”,是卷积的核心计算逻辑);bias(C_out_j):第j个输出通道的偏置项,是可选的线性偏移。N:批次大小(一次训练/推理的样本数量);C_in:输入通道数(比如RGB图像是3通道);H, W:输入特征图的高、宽(单位:像素);C_out:输出通道数(对应卷积核的数量,每个卷积核学习一组独立的特征);H_out, W_out:输出特征图的高、宽,由输入尺寸、卷积核大小、步幅、填充等共同决定。
池化(maxpool)

平均池化是特征的融合,最大池化是特征的汇聚(保留关键信息,降维)
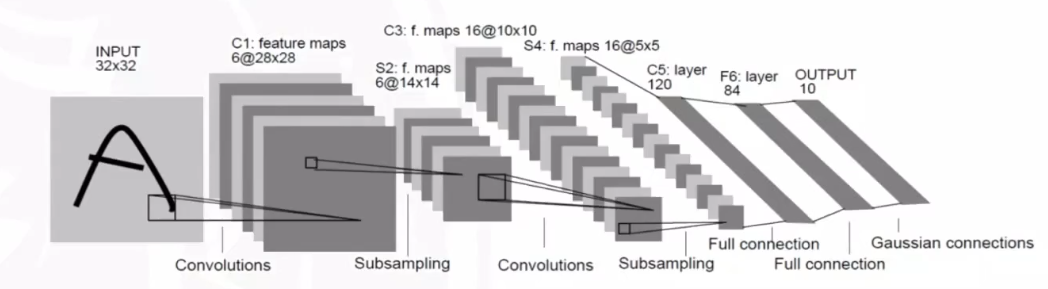
LeNet
LeNet-5模型诞生于1994年,是最早的卷积神经网络之一,由Yann LeCun完成,推动了深度学习领域的发展。其模型结构组成较为简单:两个卷积层、两个下采样、和三个全连接层。LeNet-5模型通过巧妙的设计,利用卷积、参数共享及池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别。从此卷积成为图像处理之中的可行方式。
CNN的9大变体
逐通道卷积

in_channel=out_channel=groups,可大幅降低参数量,但是在通道间信息是没有交互的,可交互的部分是每个通道的空间维度。
逐点卷积
kernel_size=1,用来解决通道维度上的问题,但办法做空间维度上的信息交互。可以通过改变卷积核的数量来升维或降维。
深度可分离卷积

先逐通道,再逐点,相较于普通卷积,还是降低了参数量。
MobileNetV1论文名称: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNetV1论文下载链接: https://arxiv.org/pdf/1704.04861.pdf
MobileNetV2论文名称: MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2论文下载链接: https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
MobileNetV3论文名称: Searching for MobileNetV3
MobileNetV3论文下载链接: http://openaccess.thecvf.com/content_ICCV_2019/papers/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.pdf
组卷积

group=n,对比常规卷积来看,虽然参数两者运算量相同,但是组卷积得到了相对于常规卷积倍的特征图数量。分组数就像一个控制旋钮,最小值是1,此时的卷积就是普通卷积。最大值是输入数据的通道数,此时的卷积就是逐通道卷积。
空间可分离卷积
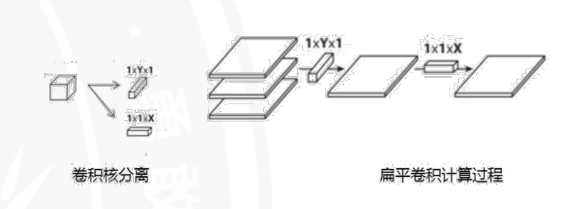
空间可分离卷积将输入特征图在横向和纵向分别进行一维卷积操作,得到最终的输出特征图。这样就可以将原来的二维卷积操作拆分成两个一维卷积操作,从而大大减少了计算量和参数数量。而且更有利于提取类似“线条”的特征(车道线识别)。
| |
膨胀卷积
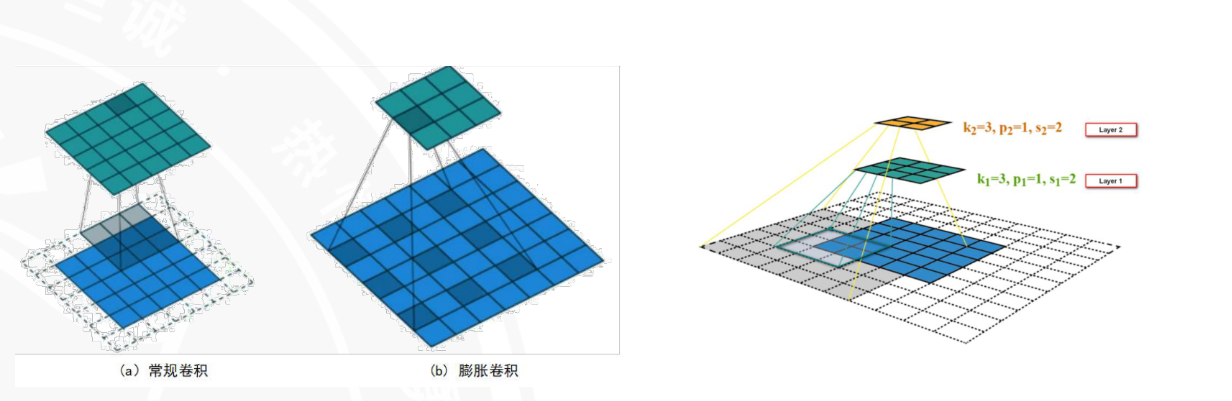
dilation=n,不会改变参数量,但是感受野增大。
转置卷积
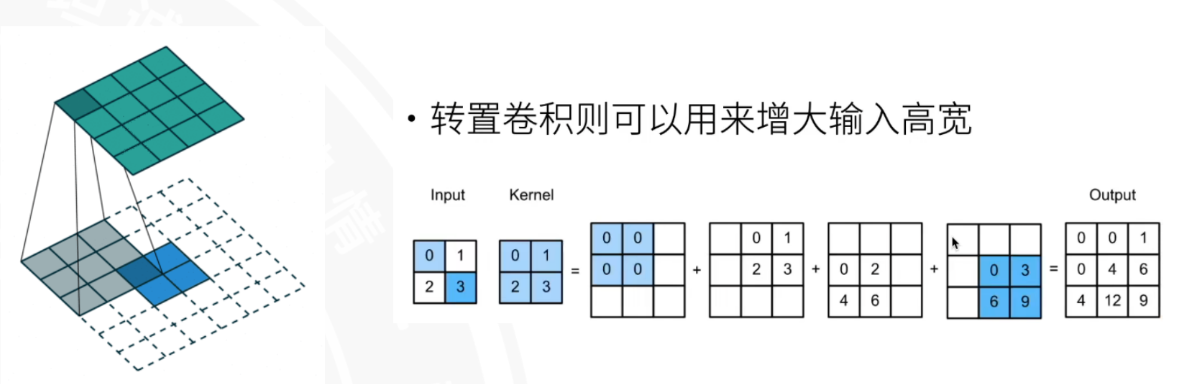
做信息的重建,可以用来增大输入高宽。torch.nn.ConvTranspose2d
1D卷积
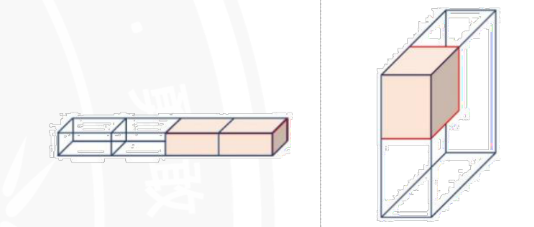
torch.nn.Conv1d,1D卷积通常用于处理序列数据,如时间序列分析、自然语言处理中的文本或任何形式的一维信号数据。通过在数据的单个维度上滑动卷积核,1D卷积能够捕捉序列内的局部特征和模式。这种方法特别适用于那些序列长度固定或可变、但数据本身具有时间或空间序列性质的应用场景。
3D卷积
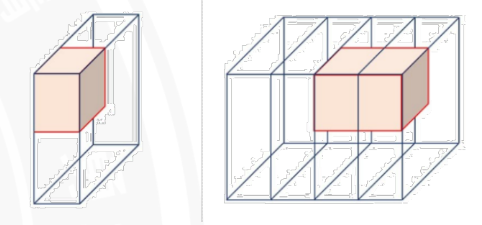
torch.nn.Conv3d,3D卷积主要用于处理3D体积数据,如在医学图像(CT扫描、MR!)分析和视频处理中。这种类型的卷积可以捕捉到数据在三个维度(通常是深度、高度和宽度)上的空间关系。对于包含时间序列的视频数据,如果我们将时间看作一个额外的维度进行处理,那么通常会使用到3D卷积,但这种情况下,3D卷积的“深度”维度通常被视为时间维度,因此可以捕获随时间变化的空间特征。