Reference
博客:
(5 封私信 / 2 条消息) AI与PDE(四):FNO与算子学习的范式 - 知乎
人工智能 - FNO:傅里叶算子神经网络 - 深度学习求解偏微分方程 - SegmentFault 思否
FNO: Fourier Neural Operator for Parametric Partial Differential Equations - BRIGHT_CZY’s site
(5 封私信) 偏微分方程与机器学习: Fourier neural operator (FNO) 详细解读 - 知乎
如何理解Fourier Neural Operator (FNO)-CSDN博客
视频:
傅里叶神经算子 Fourier Neural Operator_哔哩哔哩_bilibili
论文:
[2010.08895] Fourier Neural Operator for Parametric Partial Differential Equations
[2003.03485] Neural Operator: Graph Kernel Network for Partial Differential Equations
FNO和PINN
FNO的优势
擅长捕捉全局规律:传统神经网络(CNN、Transformer)处理高维数据时,容易丢失长程依赖关系;而FNO通过傅里叶变换将输入数据映射到频域,能直接学习 “输入场” 到 “输出场” 的全局算子映射,特别适合处理周期性、高维的科学问题。
数据效率高:在数据充足的情况下,FNO 能快速学习复杂的物理场演化规律,预测速度远超传统的有限元法、有限差分法。
泛化能力强:训练好的 FNO 模型可以快速迁移到不同的参数设置、不同的几何结构中,实现一次训练,多次复用。
FNO的局限
FNO本质上是数据驱动的模型,它只学习数据的统计规律,不保证预测结果符合物理定律。比如,在预测流体运动时,FNO可能会输出一个数学上合理但物理上错误的结果。
PINN的优势
强制遵守物理定律:通过在损失函数中加入物理损失项,PINN 能确保输出结果是物理上合理的。
数据需求低:对于数据稀缺的场景,PINN 可以仅用少量数据,结合物理约束实现高精度预测。
灵活性高:可以根据不同的物理问题,灵活调整物理损失项的形式,适配不同的科学计算场景。
PINN的局限
在处理高维、大规模的科学问题时,PINN的计算效率和泛化能力会受到限制,难以应对复杂的物理场演化。
FNO+PINN
FNO+PINN 的本质,是用 FNO 学习数据的全局模式,用 PINN 规定物理的基本法则,让模型在 “预测准确性” 和 “物理合理性” 之间找到最佳平衡点。
- FNO负责学习数据,从海量的输入数据中,学习物理场的全局演化规律,输出一个初步的预测结果。
- PINN负责验证物理,检查FNO的预测结果是否满足特定的物理方程,并通过物理损失项修正FNO的预测,确保结果符合物理常识。
算子
算子学习可以看做一种学习图像到图像映射的问题,傅里叶神经算子中的傅里叶层可以看作卷积层的替代。
- 函数类比图像,图像(本质是数组、张量)可以看作离散化的2d函数,反过来,函数可以看做高维图像。
- 算子(函数-函数映射)类比图像-图像映射,算子学习可借鉴图像处理领域的CNN网络结构
算子将一个函数映射到另一个函数,如:
\[(Fg)(x) = \int f(x,y)g(y)dy\]\[(f * g)(x) = \int f(x - y)g(y)dy\]神经算子通过神经网络学习/逼近函数映射,训练完毕的神经网络就是神经算子
FNO的切入场景与优点
求解PDE时,PDE中往往有初始条件、系数函数、源函数/驱动函数等等可变的参数函数,例如以下3个PDE案例:
- 一维Burgers方程
- 说明:初始条件 \(u_0(x)\) 是可变的参数函数。
- 二维Darcy Flow方程(稳态解)
- 说明:扩散系数函数 \(a(x)\) 和外力函数 \(f(x)\) 都是可变的参数函数。
- 二维Navier-Stokes方程(不可压缩流演化)
说明:对于含时PDE,前期的方程解作为输入(参数函数),预测后期解的时间演化。
FNO根据PDE的参数函数预测PDE的解,学习两个无穷维函数空间之间的映射关系,能求解一族PDE。
求解PDE只是FNO的作用之一,它也能用于超分辨、逆问题等场景,求解PDE是设计FNO的切入点。
通过引入傅里叶变换(fft&ifft),FNO能够更快速(1000x)、更准确地求解PDE。
FNO与具体的离散化方式无关,误差也与分辨率无关,天然适合超分辨应用。
概述
FNO的核心是学习函数到函数的映射,首先定义输入、输出函数空间:
$$ \begin{align*} A &= A(D; \mathbb{R}^{d_a}) \\ U &= U(D; \mathbb{R}^{d_u}) \end{align*} $$$$ G^\dagger: A \to U $$符号说明
- \(D\) 代表函数定义域,\(D \subset \mathbb{R}^d\),是 \(d\) 维实向量空间的有界开子集(一个“规则盒子”)。注意:FNO的输入与输出定义域相同。
- 函数空间 \(A\):每个元素代表一个函数,定义域为 \(D\),取值为 \(d_a\) 维实空间 \(\mathbb{R}^{d_a}\) 中的元素。
- 函数空间 \(U\):每个元素代表一个函数,定义域为 \(D\),取值为 \(d_u\) 维实空间 \(\mathbb{R}^{d_u}\) 中的元素。
- \(A\) 是FNO的输入函数空间,代表PDE的可变参数函数(如初始条件、系数函数、源函数等)。
- \(U\) 是FNO的输出函数空间,代表PDE的解。
- \(G^\dagger\) 是函数空间 \(A \to U\) 之间的映射,通常是复杂的非线性映射。FNO的目标就是从数据中学习到这个映射 \(G^\dagger\)。
数据集为 \(N\) 个函数对:
$$ \{a_j, u_j\}_{j=1}^N $$- \(a_j \in A\):从函数空间 \(A\) 中,根据概率测度 \(\mu\) 采样得到。
- \(u_j = G^\dagger(a_j)\):是函数空间 \(U\) 中的函数,可能带有噪声与误差。
训练过程
- 构建参数化算子:\(G_\theta: A \to U\)
- 定义代价函数:\(Cost(*, *)\) 用于比较预测输出函数 \(G_\theta(a_j)\) 与目标函数 \(u_j\) 的偏差。
- 损失函数定义:数据集的平均偏差 $$ Loss = \mathbb{E}_{a \sim \mu}\left[Cost\big(G_\theta(a), G^\dagger(a)\big)\right] \approx \frac{1}{N} \sum_{j=1}^N Cost\big(G_\theta(a_j), u_j\big) $$
- 训练目标:找到使Loss最小的参数 \(\theta\) $$ \min_\theta \mathbb{E}_{a \sim \mu}\left[Cost\big(G_\theta(a), G^\dagger(a)\big)\right] $$
NOTE:虽然理论分析是在无穷维函数空间中进行的,但在实际神经网络实现时,是用有限维空间来近似的。
函数离散化表征
在具体实现中,每一对数据 \((a_j, u_j)\) 都是定义在 \(D\) 中的两个函数。神经网络无法直接处理连续函数,因此需要用函数的离散点阵来表征该函数。例如,用 \(n\) 个离散样本点来表示 \(a_j\):
$$ \{(x_1, a_j(x_1)), (x_2, a_j(x_2)), \dots, (x_n, a_j(x_n))\} $$核心要点
- \(D_j = \{x_1, x_2, \dots, x_n\}\) 是定义域 \(D\) 中的 \(n\) 个样本点,\(a_j(x_1), a_j(x_2), \dots, a_j(x_n)\) 是 \(\mathbb{R}^{d_a}\) 中的 \(d_a\) 维向量。
- 一般 \(x_1, x_2, \dots, x_n\) 的选择是固定不变的,我们用 \(a_j\) 的 \(n\) 个函数值 \(a_j(x_1), \dots, a_j(x_n)\) 来表征 \(a_j\),并将其排列为 \(n \times d_a\) 的矩阵(或高维张量,取决于定义域的维度),记作: $$ a_j|_{D_j} \in \mathbb{R}^{n \times d_a} $$
- 同理,表征 \(u_j\) 用: $$ u_j|_{D_j} \in \mathbb{R}^{n \times d_u} $$
- 输入与输出函数在相同的定义域中,使用同一套样本点来表征。
- 关键特性:虽然FNO的输入输出都是离散化的矩阵/张量,但FNO与具体的离散化方式无关(即 discretization invariant),它可以输出任意一点 \(x \in D\) 的值 \(u_j(x)\),而不仅仅是 \(D_j\) 离散格点上的值。
FNO网络结构与计算流程
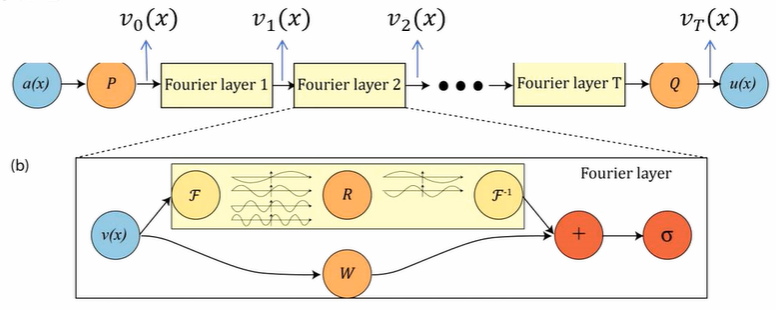
FNO的输入是代表函数 \(a(x)\) 的 \(n\) 个 \(d_a\) 维样本向量,即一个 \(n \times d_a\) 的矩阵,其计算流程分为以下几个阶段:
- 输入升维(Encoder)
首先,输入经过一个局部变换 \(P\):
$$ v_0(x) = P(a(x)) $$- \(P: \mathbb{R}^{d_a} \to \mathbb{R}^{d_v}\) 是一个浅层全连接神经网络,它将每个 \(d_a\) 维的样本向量提升为 \(d_v\) 维的特征向量,是一个升维过程,可看作 Encoder。
- 多层Fourier Layer迭代
FNO采用迭代架构,将多层Fourier Layer串联,逐步提取特征向量(类似CNN)。
- 每个 \(v_j(x)\) 是和 \(a(x)\) 定义域相同(都是 \(D\))、采样点相同的函数,用 \(n \times d_v\) 矩阵表示:\(v_j(x) \in \mathbb{R}^{n \times d_v}\)。
- 特征变换序列:\(v_0(x) \to v_1(x) \to \dots \to v_T(x)\)。
在每个Fourier Layer内部,核积分算子(Kernel Integral Operator) \(K_\phi(a)\) 与线性变换 \(W: \mathbb{R}^{d_v} \to \mathbb{R}^{d_v}\) 并联,结果相加后再经过非线性激活函数 \(\sigma\):
$$ v_{t+1}(x) = \sigma\big(W v_t(x) + \big(K_\phi(a) v_t\big)(x)\big) $$- 输出降维(Decoder)
最后,通过一个局部变换 \(Q\)(作用类似 \(P\)),将最终特征映射为输出函数 \(u(x) \in \mathbb{R}^{n \times d_u}\):
$$ u(x) = Q(v_T(x)) $$- \(Q: \mathbb{R}^{d_v} \to \mathbb{R}^{d_u}\) 是一个降维投影过程,可看作 Decoder。
核积分算子
核积分算子 \(K_\phi(a)\) 是Fourier Neural Operator的核心模块,它接收一个函数并输出一个新函数。
- 一般形式
核积分算子的定义为:
$$ \big(K_\phi(a) v_t\big)(x) = \int_D \kappa_\phi\big(x, y, a(x), a(y)\big) v_t(y) dy $$- 其中 \(x, y \in \mathbb{R}^d\),输入函数 \(a(x), a(y) \in \mathbb{R}^{d_a}\),特征向量 \(v_t(x) \in \mathbb{R}^{d_v}\)。
- 输出函数 \(\big(K_\phi(a) v_t\big)(x) \in \mathbb{R}^{d_v}\),因此核函数 \(\kappa_\phi\) 本质是一个 \(d_v \times d_v\) 的矩阵,算子可记为: $$ K_\phi: \mathbb{R}^{2(d+d_a)} \to \mathbb{R}^{d_v \times d_v} $$
- 施加约束得到卷积算子
为了简化计算并引入傅里叶变换,我们对核函数施加两个关键约束:
- 不依赖输入函数:\(\kappa_\phi\big(x, y, a(x), a(y)\big) = \kappa_\phi(x, y)\)
- 平移不变性:\(\kappa_\phi(x, y) = \kappa_\phi(x - y)\)
在这两个约束下,核积分算子退化为卷积算子:
$$ \big(K_\phi(a) v_t\big)(x) = \int_D \kappa_\phi(x - y) v_t(y) dy = (\kappa_\phi * v_t)(x) $$- 施加约束的合理性
- 不依赖输入函数 \(a(x)\):实验表明,即使让核函数依赖 \(a(x)\),模型性能也没有显著提升,反而会增加计算复杂度。
- 空间平移不变性:
- 许多具有物理背景的PDE满足平移不变性,这源于物理规律的伽利略相对性原理。
- 卷积操作(如CNN)已在多个领域证明其有效性,能有效提取平移不变的特征。
FNO核心:用傅里叶变换计算卷积
- 卷积的傅里叶变换性质
根据卷积定理,两个函数卷积的傅里叶变换等于它们各自傅里叶变换的乘积:
$$ \mathcal{F}\big[(\kappa_\phi * v_t)(x)\big] = \mathcal{F}\big[\kappa_\phi(x)\big] \times \mathcal{F}\big[v_t(x)\big] $$逆变换形式为:
$$ (\kappa_\phi * v_t)(x) = \mathcal{F}^{-1}\big(\mathcal{F}\big[\kappa_\phi(x)\big] \times \mathcal{F}\big[v_t(x)\big]\big),\; \forall x \in D $$- 周期函数假设与频域核
假设核函数 \(\kappa_\phi(x)\) 是周期函数(在定义域 \(D\) 外做周期延拓),记其傅里叶变换为:
$$ \mathcal{F}\big[\kappa_\phi(x)\big] = R_\phi $$则卷积可简化为:
$$ (\kappa_\phi * v_t)(x) = \mathcal{F}^{-1}\big(R_\phi \times \mathcal{F}\big[v_t\big]\big)(x) $$- 我们不直接构建参数化的空间域核 \(\kappa_\phi\),而是直接在频域中构建参数化的卷积核 \(R_\phi\)(乘法核)。
- 算子 \(\mathcal{F}^{-1}\big(R_\phi \times \mathcal{F}[\cdot]\big)\) 被称为傅里叶积分算子。
频域计算的优势
简化映射学习:复杂的微分方程在频域中可能转化为简单的代数方程,模型更容易学习函数之间的映射关系。
计算效率极高:通过
FFT → 频域乘法 → IFFT的流程,可将卷积计算的时间复杂度从 \(O(n^2)\) 降至 \(O(n \log n)\),大幅加速计算。
傅里叶变换的实现
输入 \(v_t(x)\) 是定义在 \(d\) 维向量 \(x \in \mathbb{R}^d\) 上的函数,输出为 \(d_v\) 维向量 \(v_t(x) \in \mathbb{R}^{d_v}\)。 计算 \(\mathcal{F}[v_t(x)]\) 时,需要对 \(v_t(x)\) 的每个分量(共 \(d_v\) 个)分别做高维(\(d\) 维)傅里叶变换。
- 函数拆分
首先,将 \(v_t(x)\) 拆分为 \(d_v\) 个标量函数 \(f_l(x_1, x_2, \dots, x_d)\)(\(l=1,2,\dots,d_v\)):
$$ v_t(x) = \begin{pmatrix} f_1(x_1, x_2, \dots, x_d) \\ f_2(x_1, x_2, \dots, x_d) \\ \vdots \\ f_{d_v}(x_1, x_2, \dots, x_d) \end{pmatrix} $$- 连续傅里叶变换
对每个标量函数 \(f_l(x)\) 进行 \(d\) 维傅里叶变换:
$$ (\mathcal{F} f)_l(k_1, k_2, \dots, k_d) = \int_D f_l(x_1, x_2, \dots, x_d) \exp\left(-2i\pi \left(k_1 x_1 + k_2 x_2 + \dots + k_d x_d\right)\right) dx_1 dx_2 \dots dx_d $$- 离散傅里叶变换(FFT)
实际运算中使用FFT计算离散傅里叶变换,要求输入维度做均匀离散化。 假设在 \(d\) 个维度上分别有 \(s_1, s_2, \dots, s_d\) 个均匀离散点,总离散点数为 \(n = s_1 \times s_2 \times \dots \times s_d\)。
离散傅里叶变换公式为:
$$ (\mathcal{F} f)_l(k_1, k_2, \dots, k_d) = \sum_{x_1=0}^{s_1-1} \sum_{x_2=0}^{s_2-1} \dots \sum_{x_d=0}^{s_d-1} f_l(x_1, x_2, \dots, x_d) e^{-2i\pi \frac{x_1 k_1}{s_1}} e^{-2i\pi \frac{x_2 k_2}{s_2}} \dots e^{-2i\pi \frac{x_d k_d}{s_d}} $$- 张量形式与实现要点
- 若 \(f_l(x)\) 用长度为 \(n\) 的向量表示,在做FFT前(例如用
pytorch.fft.fftn),需要将其变形为 \(s_1 \times s_2 \times \dots \times s_d\) 的张量。 - 变换后的 \(f_l(k)\) 是相同形状的张量,所有 \(d_v\) 个 \(f_l(k)\) 组合成一个 \(s_1 \times s_2 \times \dots \times s_d \times d_v \times 1\) 的复数张量。
- 同理,核函数 \(\kappa_\phi(x)\) 可拆分为 \(d_v \times d_v\) 个标量函数,其傅里叶变换 \(R_\phi = \mathcal{F}[\kappa_\phi(x)]\) 是一个 \(s_1 \times s_2 \times \dots \times s_d \times d_v \times d_v\) 的复数张量。
频域截断与离散化不变性
如果不做处理,频域核 \(R_\phi\) 是一个 \(s_1 \times s_2 \times \dots \times s_d \times d_v \times d_v\) 的复数张量,其形状会随离散化点数 \(s_1, s_2, \dots, s_d\) 变化,这违背了FNO“模型与离散化方式无关”的设计目标。我们希望无论 \(s_1, s_2, \dots, s_d\) 如何取值,\(R_\phi\) 的形状都保持不变。
- 频率分量的映射关系
假设维度 \(j\) 上的均匀采样间隔为 \(\Delta_j\),采样频率为 \(f_s = 1/\Delta_j\)。根据奈奎斯特采样定理,离散采样只能覆盖频率范围 \([-f_s/2, f_s/2]\)。 当离散索引 \(k_j\) 从 \(0 \sim s_j-1\) 取值时,它对应的实际频率为:
$$ freq = \begin{cases} \displaystyle \frac{k_j}{s_j} f_s &\text{若 } \frac{k_j}{s_j} \le \frac{1}{2} \\ \displaystyle \left(\frac{k_j}{s_j} - 1\right) f_s &\text{若 } \frac{k_j}{s_j} > \frac{1}{2} \end{cases} $$- 频域截断的实现
用 \(k_{max,j}\) 表示维度 \(j\) 上的截断频率,即只保留 \(k_j \le k_{max,j}\) 或 \(s_j - k_j \le k_{max,j}\) 的频率分量,大于 \(k_{max,j}\) 的频率分量将被丢弃。
- 有效频率位置:被保留的有效 \(k_j\) 都位于 \(s_1 \times s_2 \times \dots \times s_d\) 张量的“角上”。
- 截断后张量形状:每个维度 \(j\) 有 \(2 \cdot k_{max,j} + 1\) 种取值,因此截断后的 \(R_\phi\) 是一个: $$ (2k_{max,1}+1) \times (2k_{max,2}+1) \times \dots \times (2k_{max,d}+1) \times d_v \times d_v $$ 的张量。
- 共轭对称性:由于实函数频谱的共轭对称性,\(R_\phi\) 只有一半是独立参数,另一半是其复共轭。
- 离散化不变性的保证
频域截断保证了FNO的离散化不变性:
- 截断后能表示的频率范围是: $$ \left[-\frac{k_{max,j}}{s_j \Delta_j},\; \frac{k_{max,j}}{s_j \Delta_j}\right] $$
- 频域分辨率为 \(1/(s_j \Delta_j)\)。
- 因为 \(s_j \Delta_j\) 是常数(等于定义域 \(D\) 在该维度的长度,定义域必须是规则的),所以可表示的频率范围和频域分辨率与具体的离散化方式无关。
- 这一特性让FNO可以用低分辨率数据训练,然后零样本(zero-shot)迁移到高分辨率的离散化网格中。
FNO计算流程补充与逆傅里叶变换
周期函数假设 之前假设核函数 \(\kappa_\phi(x)\) 是周期函数(满足周期边界条件),因此 \(1/(s_j \Delta_j)\) 恰好是傅里叶级数展开的基频。 \(R_\phi\) 是对 \(\kappa_\phi(x)\) 离散频谱的低频截断。即使 \(\kappa_\phi\) 不是周期函数,从 \(R_\phi\) 的离散频谱信息也只能恢复出一个近似 \(\kappa_\phi\) 的周期延拓函数。
计算复杂度 FNO的核心计算流程为
FFT → 频域乘法 → IFFT,主要计算量集中在FFT和IFFT上,时间复杂度为 \(O(n \log n)\),这也是FNO计算效率高的主要原因。张量操作细节 实际计算时,截断后的 \(R_\phi\) 需要通过补零(padding)和变形(reshape),变回 \(s_1 \times s_2 \times \dots \times s_d \times d_v \times d_v\) 的张量,才能与 \(\mathcal{F}[v_t(x)]\)(形状为 \(s_1 \times s_2 \times \dots \times s_d \times d_v \times 1\))进行批量矩阵乘法。
逆傅里叶变换:
离散逆傅里叶变换的公式为:
$$ (\mathcal{F}^{-1} f)_l(x_1, x_2, \dots, x_d) = \sum_{x_1=0}^{s_1-1} \sum_{x_2=0}^{s_2-1} \dots \sum_{x_d=0}^{s_d-1} f_l(k_1, k_2, \dots, k_d) e^{2i\pi \frac{x_1 k_1}{s_1}} e^{2i\pi \frac{x_2 k_2}{s_2}} \dots e^{2i\pi \frac{x_d k_d}{s_d}} $$这一步将频域的计算结果转换回空间域,得到最终的特征向量更新。
FNO 关键特性与超参数
- 表达能力保障
虽然卷积核的频域表示 \(R_\phi\) 截断了高频成分,并对 \(\kappa_\phi\) 施加了周期边界假设,但这并不影响FNO的整体表达能力。
- 因为 Fourier Layer 中的线性变换 \(W\),以及首尾的升维/降维模块 \(P\)、\(Q\),可以帮助模型恢复高频成分和非周期特性。
- 离散化不变性的来源
离散网格的大小、数量会影响FFT/IFFT操作和频域离散表示(如频域网格的数目),但不会影响频域网格大小和频域分辨率。
- 核心原因:截断操作固定了我们关心的频域网格的数目,使得FFT+截断的频域表示与离散化方式彻底无关。
- 频域空间中学到的参数 \(R_\phi\) 代表傅里叶级数的线性组合系数,本质上是连续的,因此 \(R_\phi\) 与 \(\kappa_\phi\) 是连续的映射关系。
- 零样本超分辨率
得益于离散化不变性,FNO可以:
- 用低分辨率网格进行训练
- 用高分辨率网格进行推理
- 这种能力被称为 zero-shot super-resolution,让FNO非常适合超分辨重建任务。
- 论文中的典型超参数
- 网络结构:4层 Fourier Layer
- 激活函数:ReLU
- 优化器:Adam
- 特征维度:\(d_v\) 取 64 或 32
- 截断频率:\(k_{max,j}\) 取 16 或 12
- 输入维度:\(d\) 一般不超过 3 维
- 硬件需求:仅需单块 16GB V100 显卡即可完成实验
补充
补充一:FNO 的研究动机
- 传统 PDE 求解的分辨率问题
传统 PDE 数值方法(有限差分 / 有限元 / 谱方法)本质上都是在离散空间中求解连续方程,不可避免地存在分辨率权衡问题:
- 低分辨率网格:计算快,但数值误差大
- 高分辨率网格:精度高,但计算成本极高(时间 + 硬件)
本质在于:精度的提升依赖于离散自由度的指数级增长
这使得传统方法在:多参数 PDE;多次重复求解;实时预测等场景中成本难以接受。
- FNO 的定位
FNO 论文将现有方法大致分为三类:
(1)Finite-dimensional Operators(有限维算子)
- 输入 / 输出:固定分辨率的欧几里得空间张量 例如: $$ \mathbb{R}^{64\times64} \rightarrow \mathbb{R}^{256\times256} $$
- 本质:学习一个特定分辨率下的映射
特点:
- 对特定任务效果好
- 强依赖网格分辨率
- 更换分辨率 / 初边界条件通常需要重新训练
(2)Neural-FEM / PINNs
- 用神经网络参数化 某一个具体 PDE 解
- 训练过程 ≈ 求解过程
特点:
- 物理一致性强
- 训练成本高、难收敛
- 一旦参数 / 初始条件改变 → 需要重新训练
(3)Neural Operators(FNO 所属)
- 直接学习: $$ a \mapsto u $$ 其中 \(a\) 是 PDE 的参数函数(初值 / 系数 / 强迫项等)
- 一次训练,多次推理
- 目标:学习一族 PDE 的解算子
补充二: 从 PDE 到积分算子
- PDE 解算子视角
考虑一个带参数的 PDE:
$$ \mathcal{L}_a u = f $$其解可以写成一个算子形式:
$$ u = G_a(f) $$这里:
- \(a\):参数(可能是函数)
- \(G_a\):对应参数下的解算子
算子学习的目标是:学习 \(a \mapsto G_a\),而不是只学某一个 \(u\)
- 格林函数启发
对于线性 PDE,解可以通过格林函数表示:
$$ u(x) = \int_D G(x,y) f(y) dy $$直观理解:
- \(u(x)\) 由定义域中所有点 \(y\) 共同决定
- 影响强度由核函数 \(G(x,y)\) 决定
PDE 解天然是全局积分算子的结果,而不是局部算子
这正是 CNN(局部卷积)在 PDE 中受限的原因之一。
- 非线性 PDE 与可迭代算子网络
虽然格林函数严格成立于线性 PDE,但可以通过:
- 多层积分算子
- 非线性激活函数
构造如下的可迭代算子网络:
$$ v_{t+1}(x) = \sigma\left( W v_t(x) + \int_D \kappa(x,y) v_t(y) dy \right) $$- 下标 \(t\) 表示网络层数(非时间)
- 类似 ResNet 的残差结构
- 非线性由 \(\sigma\) 提供
补充三:为什么是 Fourier Operator
- Fourier Filter 是全局的
- CNN 卷积核 → 局部感受野
- Fourier 模态 → 全局基函数
PDE 解的特征往往是:
- 长程依赖
- 全局结构
- 与谱方法的内在联系
传统谱方法:
- 在傅里叶空间中求解 PDE
- 与离散网格弱相关
- 高精度但难处理复杂几何
FNO 的思想可以理解为:
在傅里叶空间中,用神经网络学习谱方法中未知的部分
这也是 FNO 能做到:准线性复杂度;分辨率不变性;超分辨推理的根本原因。
补充四:FNO 的实际任务设计
- Burgers 方程
- 输入:初始条件函数
- 输出:固定时间的解
- Darcy Flo
- 输入:空间变化的扩散系数
- 输出:稳态解
- Navier–Stokes
- 输入:一段时间序列
- 输出:未来演化
- 同时验证不同粘性系数下的泛化能力
本质是算子在时间维度上的外推能力。
补充五:FNO 的工程意义与发展方向
- 准线性复杂度:\(O(n \log n)\)
- 单卡即可训练 toy 问题
- 已被 NVIDIA 扩展至:
- AFNO
- 全球天气预报
- 超大规模 GPU 集群
这说明 FNO:
- 不是纯理论模型
- 是目前最接近可工业化的算子学习方法
补充六:FNO 的方法谱系与复杂度动机
Fourier Neural Operator 并非直接从傅里叶变换出发设计,而是 Neural Operator 框架在工程可行性约束下的产物。
最一般的 Neural Operator 可写为带核的积分算子,其结构等价于定义在空间点集上的全连接图神经网络,计算复杂度为:
$$ O(K^2) $$在高分辨率 PDE 场景中,这种复杂度是不可接受的。
为降低复杂度,Z. Li 等人在早期工作中依次引入了以下优化:
- 邻域限制(局部图)
- 多极展开(降低远程交互成本)
- 平移不变性与输入无关核假设
在进一步假设核函数仅依赖于相对位移 \(x-y\) 后,积分算子退化为卷积算子,从而可以通过傅里叶变换在频域中高效计算。此时,核函数在频域中的表示 \(R_\phi\) 成为模型的主要可学习参数。
因此,FNO 可以被视为:
Graph Kernel Neural Operator 在平移不变假设下、以 Fourier 模态为基的高效实现形式
这一设计在牺牲部分表达能力的同时,换取了准线性复杂度、分辨率不变性以及良好的工程可扩展性。