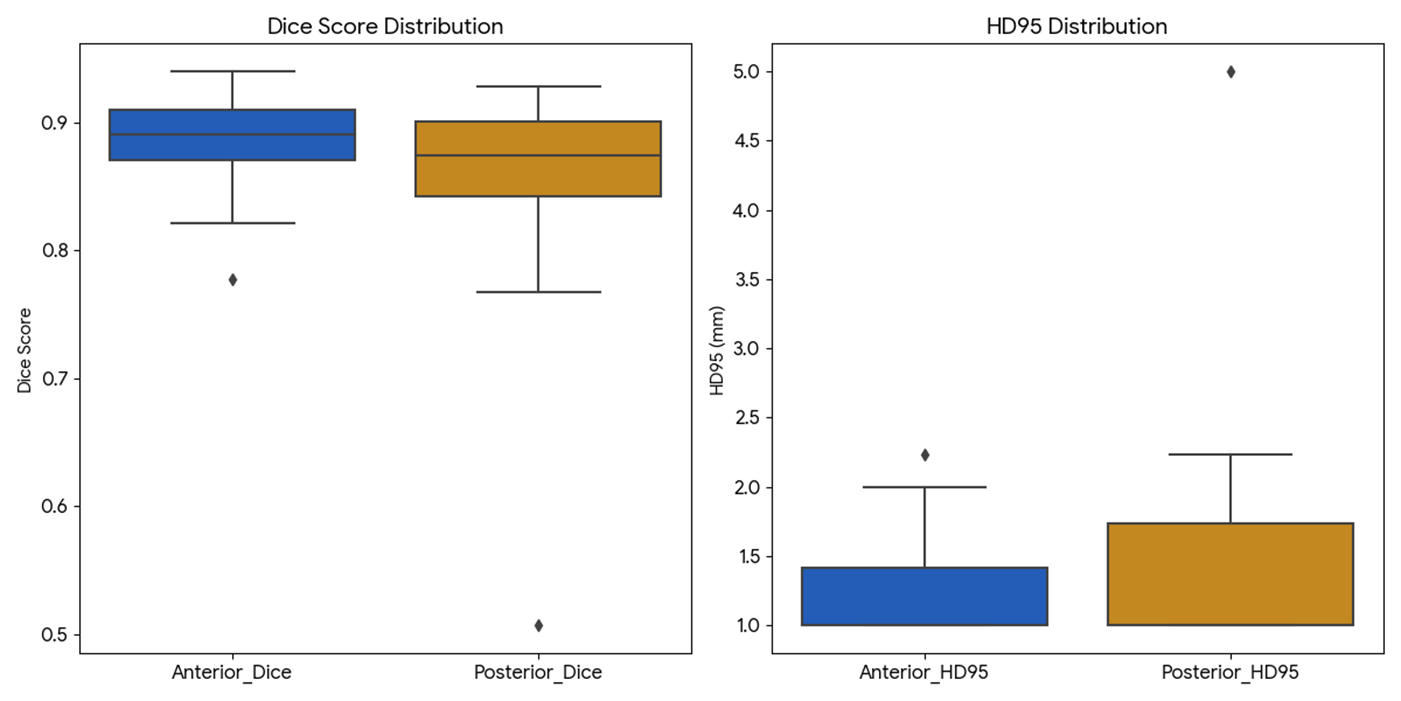
Dice
在图像分割中,通常将图像转换为二值矩阵(前景为 1,背景为 0),此时公式可表示为逐像素的计算形式:
$$
\text{Dice} = \frac{2\sum_{i,j} P_{i,j} \cdot G_{i,j}}{\sum_{i,j} P_{i,j} + \sum_{i,j} G_{i,j}}
$$其中:
- $P_{i,j}$:预测图像在 $(i,j)$ 位置的像素值。
- $G_{i,j}$:真实标注图像在 $(i,j)$ 位置的像素值。
- $\sum_{i,j}$:对图像所有像素进行求和。
在 validation_step 函数和自定义的 evaluate 脚本里的属于 hard dice,预测图是二值化的。而在训练时的是 soft dice,不把概率变成 0 和 1,而是直接用概率值去计算。dice 指标的实际含义就是预测和真值整体的重合率。且 dice 指标与交并比也有互相转化的公式。
IoU
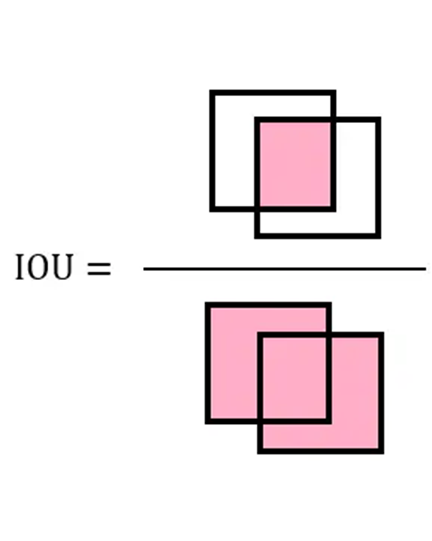
语义分割中最常用的度量标准是 IoU,也称为Jaccard系数。对于给定类别,IoU衡量预测分割掩码 (A) 与真实掩码 (B) 之间的重叠程度。IoU分数范围从0(无重叠)到1(完全重叠)。IoU分数越高,表示该类别的分割效果越好。
通常会为每个类别单独计算 IoU,然后对所有类别取平均值,得到平均交并比 (mIoU)。这提供了一个单一的、全面的分数,用于衡量模型在整个数据集或图像上的性能。
HD95
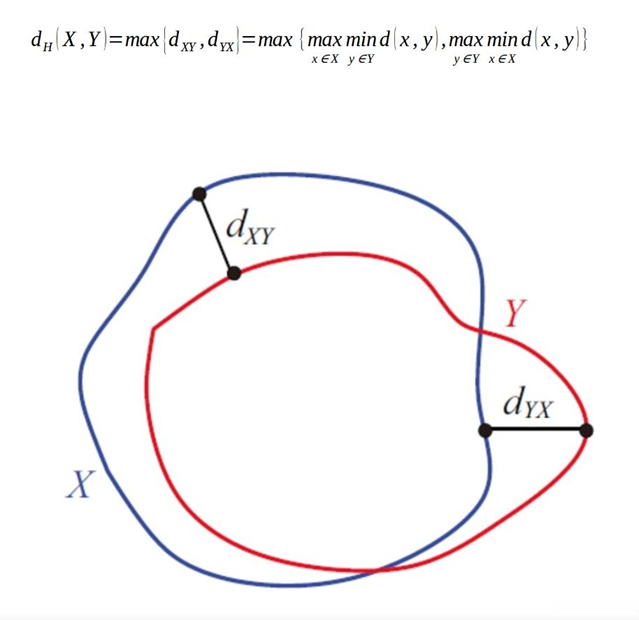
HD 代表预测偏离的最大值。但是往往个别的噪点不应该毁了整个模型的评价。因此选用HD95,砍掉前5%的最大距离。当我们调用 hd95 函数时,其实计算逻辑如下:首先,提取轮廓,先把实心的掩码(Mask)变成空心的圈(Contour),只保留边缘像素。然后计算距离图 (Distance Map),对于预测轮廓上的每一个像素,计算它到真值轮廓最近像素的欧式距离。最后,把这些距离收集起来放在一个列表里,排序,取 95% 位置的数值。这里需要注意spacing,计算机算出来是偏离了n个像素,但是不同图的单位像素代表距离不同。
P/R

其他指标
VOE:VOE = 1 – IoU,如果计算了IoU,就没必要再算。
mIoU:mIoU 是所有类别 IoU 的平均值。
Hausdorff:HD 不稳定。只要有一个噪点,HD 就会变得无限大,不能反映真实性能。
Surface Dice (NSD):太麻烦且非必须。需要设定一个阈值(比如 1mm 容差)。除非打特定的比赛,否则用 Dice + HD95 代替足够说明表面情况。
Balanced Accuracy & Kappa:过时,深度学习分割领域现在很少用这两个。
RVD (Relative Volume Difference):改为 Volume Error。单纯的 RVD 有正负,平均时会抵消。我们计算体积偏差绝对值更好。
evaluate 脚本计算指标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| import os
import numpy as np
import nibabel as nib
import pandas as pd
from tqdm import tqdm
from medpy.metric.binary import hd95, asd
# ================= 配置区域 =================
GT_FOLDER = r'/root/nnUNet/nnUNet_raw/Dataset004_Hippocampus/labelsTr'
PRED_FOLDER = r'/root/nnUNet/nnUNet_results/Dataset004_Hippocampus/nnUNetTrainer__nnUNetPlans__2d/fold_4/validation'
OUTPUT_CSV = 'task04_comprehensive_metrics.csv'
# 类别定义
CLASS_NAMES = {1: "Anterior", 2: "Posterior"}
# ===========================================
def calculate_metrics():
if not os.path.exists(GT_FOLDER) or not os.path.exists(PRED_FOLDER):
print(" 路径错误,请检查文件夹路径配置!")
return
pred_files = [f for f in os.listdir(PRED_FOLDER) if f.endswith('.nii.gz')]
results = []
print(f" 开始【·指标计算 (共 {len(pred_files)} 个样本)...")
for filename in tqdm(pred_files):
gt_path = os.path.join(GT_FOLDER, filename)
pred_path = os.path.join(PRED_FOLDER, filename)
if not os.path.exists(gt_path):
continue
# 1. 加载数据
gt_obj = nib.load(gt_path)
pred_obj = nib.load(pred_path)
spacing = gt_obj.header.get_zooms()[:3]
gt_data = gt_obj.get_fdata().astype(np.uint8)
pred_data = pred_obj.get_fdata().astype(np.uint8)
file_metrics = {'filename': filename}
for class_id, class_name in CLASS_NAMES.items():
gt_mask = (gt_data == class_id)
pred_mask = (pred_data == class_id)
# --- 基础统计 (混淆矩阵) ---
tp = np.sum(gt_mask & pred_mask)
fp = np.sum((~gt_mask) & pred_mask)
fn = np.sum(gt_mask & (~pred_mask))
# --- 1. Overlap Metrics (重叠类) ---
# Dice = 2TP / (2TP + FP + FN)
smooth = 1e-5
dice = (2.0 * tp) / (2.0 * tp + fp + fn + smooth)
# IoU = TP / (TP + FP + FN)
iou = tp / (tp + fp + fn + smooth)
# --- 2. Statistical Metrics (统计类) ---
# Precision = TP / (TP + FP) (查准率)
if (tp + fp) > 0:
precision = tp / (tp + fp)
else:
precision = 1.0 if np.sum(gt_mask) == 0 else 0.0
# Sensitivity (Recall) = TP / (TP + FN) (查全率/敏感度)
if (tp + fn) > 0:
sensitivity = tp / (tp + fn)
else:
sensitivity = 1.0 # 如果真值本来就是空的,且没预测出来,算对
# --- 3. Distance Metrics (距离类) ---
if np.sum(gt_mask) > 0 and np.sum(pred_mask) > 0:
try:
hd95_val = hd95(pred_mask, gt_mask, voxelspacing=spacing)
asd_val = asd(pred_mask, gt_mask, voxelspacing=spacing)
except:
hd95_val = np.nan
asd_val = np.nan
else:
hd95_val = np.nan
asd_val = np.nan
file_metrics[f'{class_name}_Dice'] = dice
file_metrics[f'{class_name}_IoU'] = iou
file_metrics[f'{class_name}_Precision'] = precision
file_metrics[f'{class_name}_Sensitivity'] = sensitivity
file_metrics[f'{class_name}_HD95'] = hd95_val
file_metrics[f'{class_name}_ASD'] = asd_val
results.append(file_metrics)
df = pd.DataFrame(results)
df.to_csv(OUTPUT_CSV, index=False)
print("\n" + "="*40)
print(" 评估完成!")
print("各指标平均值 (Mean):")
print(df.mean(numeric_only=True).round(4))
print(f"\n 详细报表: {os.path.abspath(OUTPUT_CSV)}")
print("="*40)
if __name__ == '__main__':
calculate_metrics()
|
Task_04项目的指标结果
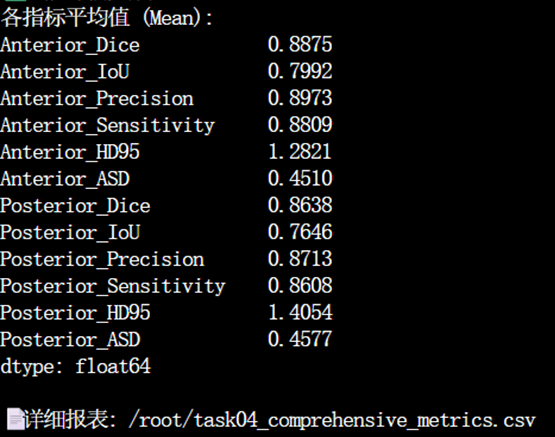
在 Task04 海马体数据集上,Dice 达到 0.88+ (前部) 和 0.86+ (后部) 是顶级水平。通常这个任务上的 baseline 就在 0.86 - 0.88 之间。
Anterior 的所有指标(Dice, IoU, HD95)都优于 Posterior 。
Anterior Dice: 0.8875 > Posterior Dice: 0.8638
Anterior HD95: 1.28mm < Posterior HD95: 1.40mm
海马体的头部 (Anterior) 结构比较宽大、特征明显;而尾部 (Posterior) 逐渐变细,边界模糊,且容易受到周围组织的干扰。模型在难分区域表现稍弱,证明它没有过拟合,而是真实反映了数据的难度。
对比 Precision (查准率) 和 Sensitivity (查全率)。
Anterior: Precision (0.8973) > Sensitivity (0.8809)
Posterior: Precision (0.8713) > Sensitivity (0.8608)
Precision 高意味着:模型预测是海马体的地方,几乎都是对的(误报少)。
Sensitivity 稍低意味着:模型漏掉了一小部分真实的边缘。
ASD (0.45mm):意味着平均误差只有 0.45 mm。Task04 的图像分辨率大概是 1mm^3。平均误差不到半个像素。