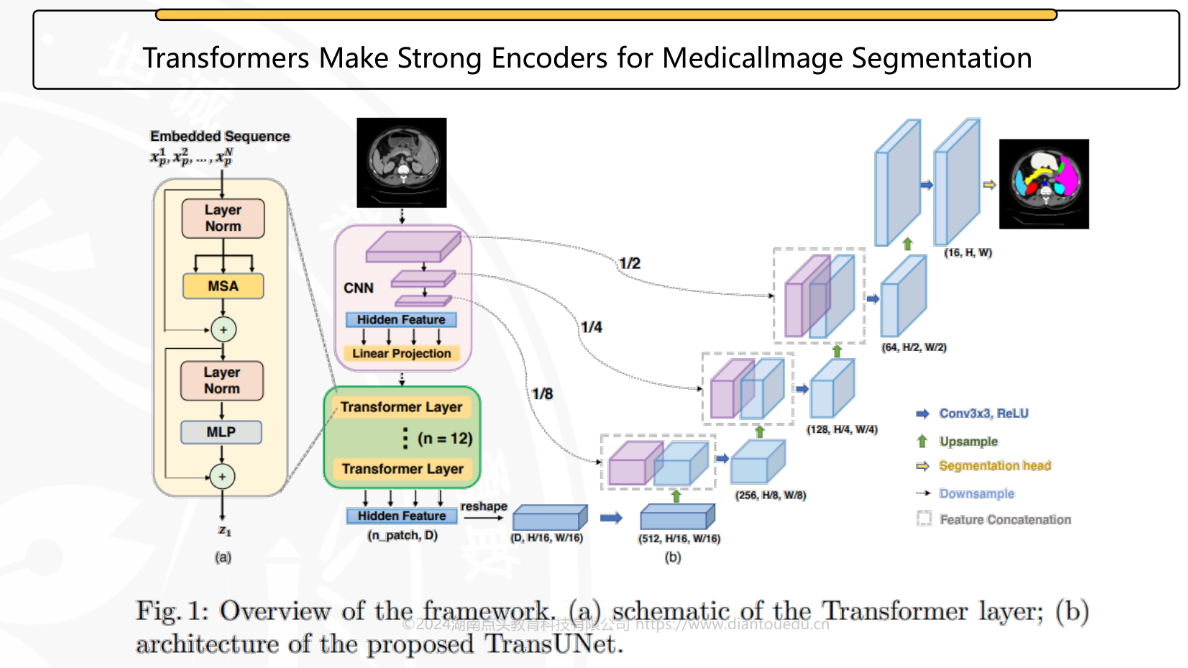
U-Net学习
概论
其实就是FCN的改良版本,丢失几个像素信息是正常的。
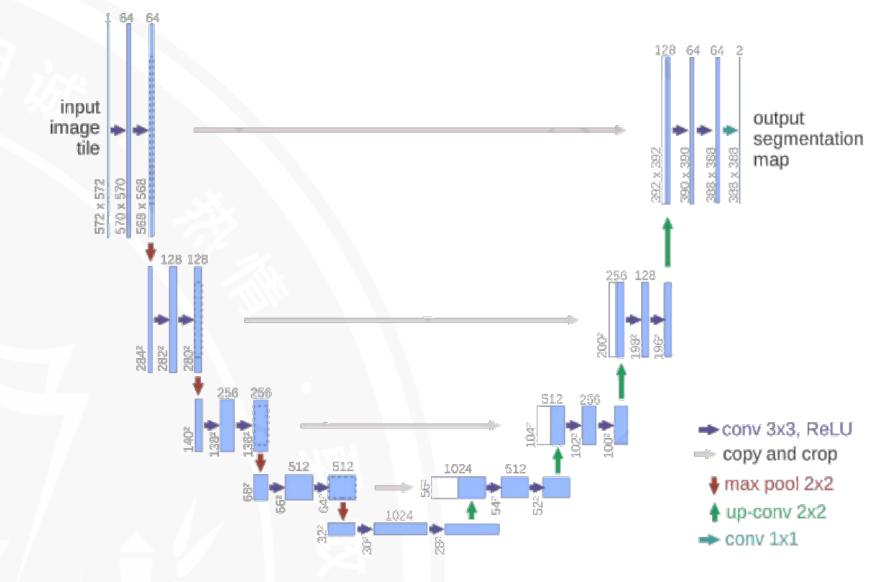
Encoder
下采样,就是上面图片中的左半边部分,
编码器通过卷积(Conv)和下采样(最大池化,max pool)操作,逐步提取图像的高层特征,同时缩小特征图的尺寸,实现“压缩空间维度、提升通道维度(特征表达能力)”的效果。
- 输入(input image tile):
输入图像尺寸为
572×572,经过一系列操作后,逐步缩小尺寸、增加通道数。 - 卷积(conv 3×3, ReLU):
用
3×3的卷积核提取特征,ReLU 激活函数引入非线性,增强模型表达能力。例如初始阶段通道数从 1(假设灰度图)或 3(RGB 图)提升到 64,再到 128、256 等。 - 最大池化(max pool 2×2,红色箭头):
对特征图进行
2×2下采样,尺寸缩小一半,通道数不变。这一步是“缩小空间维度、保留关键特征”的关键操作,比如从264×264缩小到132×132,同时通道数维持 128。
Bridge和Decoder
编码器最终输出的高维特征(比如图中最后阶段的 28×28×512 特征图)会传递给解码器(Decoder,图中右侧部分),解码器通过上采样和特征融合,逐步恢复图像尺寸,最终输出分割图(output segmentation map)。
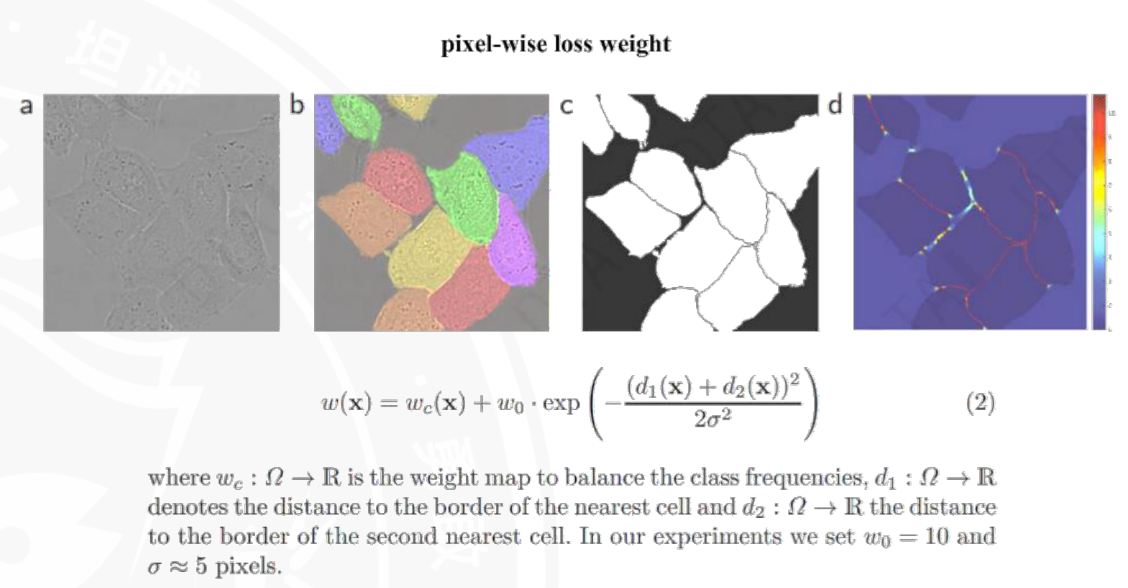
这张图讲解的是像素级损失权重的设计,用于解决语义分割中“类别不平衡”和“边界像素难分割”的问题。
图像部分(a-d) 可以看到细胞边界区域权重更高,这是为了让模型更关注难分割的边界像素。
图a:原始输入图像。
图b:不同细胞的类别标注。
图c:细胞的边界标注。
图d:最终的像素损失权重可视化(颜色越亮,权重越高)。
公式与符号解释:$w(\mathbf{x}) = w_c(\mathbf{x}) + w_0 \cdot \exp\left(-\frac{(d_1(\mathbf{x}) + d_2(\mathbf{x}))^2}{2\sigma^2}\right)$
$w(\mathbf{x})$:像素$\mathbf{x}$的最终损失权重,权重越高,模型在训练时对该像素的预测误差越重视。
$w_c(\mathbf{x})$:用于平衡类别频率的权重(比如某些细胞类别像素少,$w_c$就会调高,避免模型忽略小众类别)。
$w_0, \sigma$:超参数(实验中设$w_0=10$,$\sigma\approx5$像素),控制边界权重的强度和范围。
$d_1(\mathbf{x})$:像素$\mathbf{x}$到“最近细胞边界”的距离。
$d_2(\mathbf{x})$:像素$\mathbf{x}$到“第二近细胞边界”的距离。
公式中的指数项是为了让靠近细胞边界的像素获得更高权重,距离边界越近,$d_1+d_2$越小,指数项的值越大,最终$w(\mathbf{x})$越高,模型就会更关注这些难分割的边界区域。
PointRend模型
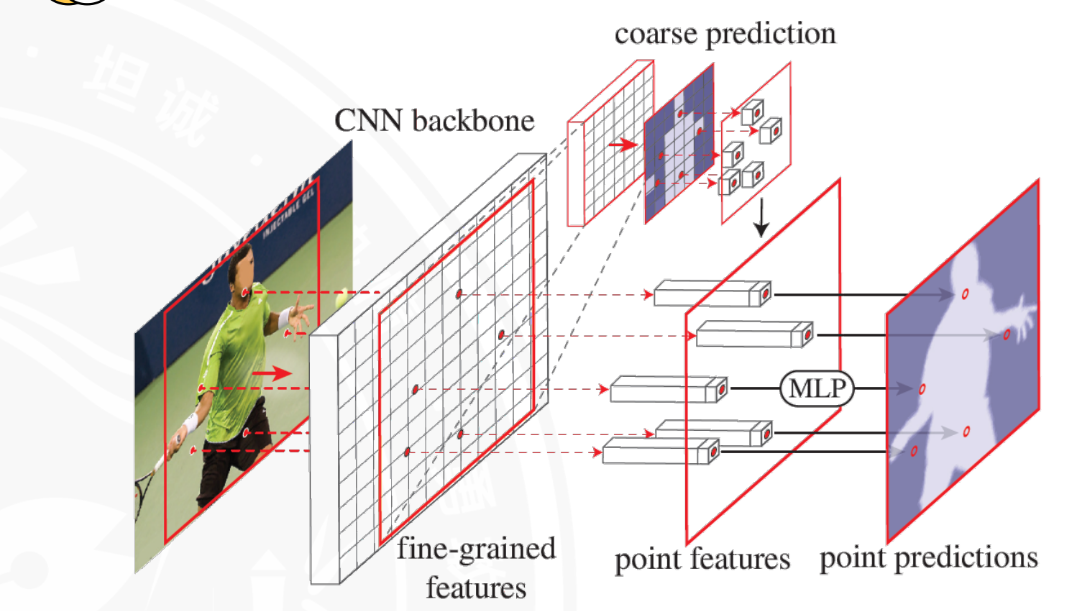
TransUNet模型